Schrijven met de pen van je moedertaal
Janine Berns & Sanne van Vuuren, Radboud Universiteit
Meer dan alleen ‘goed’ of ‘fout’
Het zal voor velen herkenbaar zijn dat je bij het leren van een nieuwe taal vrijwel automatisch in een mindset schiet waarin je focust op dingen die “goed” of “fout” gaan. Je docent baseert er je cijfer op tijdens een toets, en bij apps als Duolingo bepalen je goede en foute antwoorden de score die je aan het eind van iedere oefening in beeld te zien krijgt. Maar als je zo’n nieuwe taal meer en meer gaat beheersen, komt er ook een moment dat je geen, of vrijwel geen, echte fouten meer maakt. Uitspraak, spelling en grammatica heb je goed onder de knie en je gebruikt de taal met veel gemak. Maar ook al gebruik je klanken, woorden en constructies die in de doeltaal bestaan, ook op de hele gevorderde niveaus van taalbeheersing kunnen bepaalde talige voorkeuren uit je moedertaal in de doeltaal blijven doorsijpelen. Dit zorgt dan niet meer voor fouten, maar het geeft een bepaalde kleuring aan je taalgebruik.
Waar je dit bijvoorbeeld terugziet is in teksten die worden geschreven door gevorderde leerders van het Engels. In een onderzoek naar schrijfvaardigheidsontwikkeling hebben we gekeken naar de manier waarop gevorderde leerders woordgroepen die een persoonlijk voornaamwoord of zelfstandig naamwoord bevatten, steeds complexer maken. Aan wat voor constructies moet je dan denken? Stel, er is een situatie waarin een rode fiets met zwarte handvatten uit de gracht wordt gevist. Je kunt deze informatie verpakken in twee losse hoofdzinnen: ‘A bike was dredged out of the canal. It has a red frame and black handlebars’. Op zich prima zinnen, en zeker in mondeling taalgebruik kun je vast wel aan een situatie denken waarin je beide zinnen ook zo direct na elkaar zou kunnen uitspreken. In schriftelijk taalgebruik, vooral wanneer het om een meer formeel of academisch register gaat, is het passender de informatie uit beide hoofdzinnen samen te voegen in een complexere zin. Dat kan met een betrekkelijke bijzin als ‘The bike that was dredged out of the canal has a red frame and black handlebars’, of met een deelwoordzin als ‘The bike dredged out of the canal has a red frame and black handlebars’.
Onderzoek en resultaten
We waren benieuwd naar hoe je het gebruik van dergelijke constructies terugziet bij studenten die dagelijks bezig zijn om academisch en formeel schrijven in het Engels onder de knie te krijgen. Ook wilden we weten in welk opzicht vreemdetaalleerders van het Engels verschillen van moedertaalsprekers van deze taal. Daarom hebben we argumentatieve teksten uit het International Corpus of Learner English (ICLE, 2002), geschreven door Nederlandstalige en Franstalige leerders van het Engels, vergeleken met soortgelijke teksten uit het Louvain Corpus of Native English Essays (LOCNESS, Granger, 1998), geschreven door moedertaalsprekers van het Engels. Om een beter zicht te krijgen op eventuele moedertaalinvloed hebben we aanvullend Nederlandse teksten geschreven door moedertaalsprekers geanalyseerd (uit het LONGDALE corpus, Meunier, 2016). Alle teksten uit de verschillende datasets zijn afkomstig van studenten die een universitaire studie Engels volgden.
Onze resultaten laten het volgende zien. Als je allereerst kijkt naar de frequentie waarmee de verschillende schrijversgroepen een complexe naamwoordzin gebruiken, zie je dat deze voor de Nederlandse leerders heel dicht in de buurt ligt bij die van hun Engelstalige leeftijdsgenoten. Een dergelijke constructie komt 13.55 keer per 1000 woorden voor in een tekst geschreven door een moedertaalspreker, en 13.33 keer bij een Nederlandse leerder. Met 10.75 keer per 1000 woorden worden de complexe nominale structuren in de teksten van de Franstalige leerders, significant minder vaak gebruikt. Deze verschillen lijken voornamelijk samen te hangen met het niveau van syntactische ontwikkeling van de verschillende studenten, want ook op basis van andere indicatoren van zinscomplexiteit waar we naar hebben gekeken, blijkt het niveau van de Franstalige leerders iets onder dat van de Nederlanders te liggen.
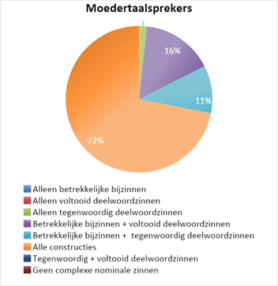
Als we vervolgens inzoomen op de variatie aan structuren die worden gebruikt, komt weer een heel ander patroon naar voren. In 72% van de teksten geschreven door de moedertaalsprekers worden zowel betrekkelijke bijzinnen, voltooid deelwoordzinnen als tegenwoordig deelwoordzinnen gebruikt. Dit percentage bedraagt 45% voor de Nederlandse leerders en 28% voor de Franstaligen. Opvallend daarbij is dat in teksten waarin minder variatie aan structuren te zien is, de moedertaalsprekers nooit enkel betrekkelijke bijzinnen gebruiken, maar ook gebruikmaken van óf tegenwoordig óf voltooid deelwoordzinnen. Bij de Nederlandstalige leerders daarentegen zien we dat toch zo’n 17% enkel betrekkelijke bijzinnen gebruikt, bij de Franstaligen is dit 22%. De diagrammen hieronder geven een nog vollediger beeld van hoe de verschillende combinaties van structuren per tekst voor de verschillende schrijversgroepen zijn verdeeld.
Het plaatje per groep kunnen we nog gedetailleerder maken als we ook de frequentie waarmee de verschillende constructies worden gebruikt meenemen. Hoewel de Nederlandse leerders in hun gebruik van complexe nominale groepen niet onderdoen voor de moedertaalsprekers, zijn de voorkeursstructuren van beide groepen fundamenteel anders.
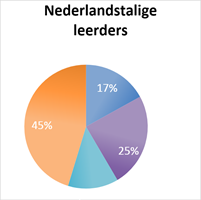
De Nederlandse leerders blijken namelijk significant meer betrekkelijke bijzinnen te gebruiken, maar juist significant minder tegenwoordig en voltooid deelwoordzinnen dan de moedertaalsprekers. En die voorkeur lijkt een directe invloed van hun moedertaal te zijn. In de Nederlandstalige argumentatieve teksten geschreven door Nederlandse studenten, blijken de betrekkelijke naamwoordzinnen namelijk ook de dominante structuur te zijn, en we zien daar dat het aandeel van deze structuur in de gebruikte patronen zelfs nog hoger is dan in de Engelstalige teksten geschreven door Nederlandse leerders.
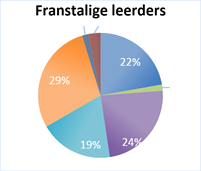
De Franstaligen in onze dataset gebruiken significant minder betrekkelijke bijzinnen in het Engels dan de Nederlandse leerders en de moedertaalsprekers. Maar deze groep valt om een andere reden op, namelijk vanwege hun gebruik van deelwoordzinnen. Hoewel ze significant minder van deze structuren gebruiken in hun teksten dan de moedertaalsprekers, gebruiken ze deze structuren duidelijk meer dan de Nederlandse leerders. Zowel de tegenwoordig als de voltooid deelwoordzinnen lijken ze dus, net als in hun moedertaal, met meer gemak en regelmaat te gebruiken dan de Nederlanders.
Tot slot
Ook wanneer het gaat om transfer denken we vaak snel in termen van moedertaalinvloed die correcte of incorrecte structuren oplevert in de doeltaal. In onze resultaten zien we duidelijk dat transfer meer is dan dat. Zowel de Nederlandse als de Franstalige leerders gebruiken structuren die in de doeltaal kunnen worden gebruikt, maar de dosering van de verschillende patronen onderscheidt de leerdersgroepen van elkaar en van hun Engelstalige leeftijdsgenoten. Op de hogere niveaus van taalbeheersing kan moedertaalinvloed zo subtiel blijven doorsijpelen dat het effect niet aan één individuele zin of een paar afzonderlijke zinnen te zien is. De Nederlandse of Franse touch is pas merkbaar als je een tekst als geheel bekijkt. Complexe nominale groepen zijn daarvan een illustratie, maar je kunt hierbij ook denken aan bijvoorbeeld de manier waarop zinnen aan elkaar worden verbonden, zinslengte of informatiestructuur.
In hoeverre je als taalleerder ook nog die laatste subtiele invloed uit je moedertaal wilt proberen weg te poetsen, hangt helemaal af van wat je doelen zijn. Wil je gewoon een goedlopende en goed leesbare tekst produceren, dan is alleen al het feit dat je met betrekkelijke bijzinnen en deelwoordzinnen kunt omgaan ongetwijfeld voldoende. Als je doel is nog een stapje verder te gaan, ‘to write like a native’, dan is dat in ieder geval een proces van langere adem, waarin je door veel te schrijven en veel authentieke teksten te lezen, uiteindelijk steeds meer gaat schrijven met de pen van de doeltaal.
Meer weten?
Granger, S. (1998). The computer learner corpus: A versatile new source of data for SLA research. In Granger, S. (Ed.). Learner English on computer (pp. 3-18). London & New York: Longman.
ICLE: International Corpus of Learner English. (2002). Granger, S., Dagneaux, E. & Meunier, F. (Eds.). Louvain-la-Neuve: Presses Universitaires de Louvain.
Meunier, F. (2016) Introduction to the LONGDALE project. In Castello, E., Ackerley, K., Coccetta, F. (Eds.). Studies in Learner Corpus Linguistics: Research and applications for foreign language teaching and assessment (pp. 123-126). Bern: Peter Lang.
terug
U moet ingelogd zijn om een reactie te kunnen plaatsen.